本篇是《深入剖析 Kubernetes》 的读书笔记,作者为张磊老师。
这几个主题需要介绍的部分都比较少,所以放在一篇博客里了。
# 调度
# 资源模型和管理
Kubernetes 里可以给容器指定分配 CPU 和内存资源的多少。
resources:
requests:
memory: "64Mi"
cpu: "500m"
limits:
memory: "128Mi"
cpu: "1"
从字面上来看,有下面几个概念:
- requests 是容器的最小资源需求,Kubernetes 会保证这个资源一直可用。
- limits 是容器的最大资源需求,Kubernetes 会限制容器使用的资源不超过这个值。
- memory 资源的单位很好理解,就是内存的大小。CPU 资源的单位是 millicores,1m = 1/1000 cores。
在字面外,还有一些细节:
- CPU 资源和内存资源有一个区别,CPU 是可压缩资源,内存是不可压缩资源。就是说,宿主机的 CPU 不够用了,可以通过时间片轮转的方式,让多个容器共享 CPU。但是内存不行,如果内存不够用了,就只能 OOMKilled 了。所以 CPU 不够用了只会持续 100% 占用,却不会有
Out Of CPU Killed这种说法。 - 为了保证容器的 requests,K8s 会在调度的时候,只会把容器调度到有足够空闲(还没有被 requests)资源的 Node 上。为了保证容器的 limits,如果容器进程申请的内存超过它的 limits 的时候,容器就可能被杀掉。
- K8s 根据 requests 和 limits,可以计算出容器的 QoS 类型,从高优先级到低优先级依次为 Guaranteed、Burstable 和 BestEffort 三种。
- Guaranteed 是 requests = limits 的情况,Burstable 是 requests != limit 的情况,BestEffort 是什么都没设置的情况。
- 当宿主的不可压缩资源(内存、宿主机磁盘空间、镜像存储空间)紧张时,会触发 Eviction:1. 优先杀掉 BestEffort 类型的容器;2.然后是 Burstable 且对应资源使用量超过 requests 的容器;3. 最后是 Guaranteed 且对应资源使用量超过 limits 的容器。
- Eviction 的触发条件都是可配置的,比如
--eviction-hard参数指定硬资源回收的触发条件,--eviction-soft和--eviction-soft-grade-period指定软资源回收的触发条件和等待时间。
- 如果一个容器是 Guaranteed 且 CPU request 是整数,K8s 会把相同数量的 CPU 绑定到容器上,这样可以避免 CPU 的频繁切换,提高性能。
所以对于一个 web 服务,最好是设置为 Guaranteed 类型,虽然申请过量的 CPU、内存资源会导致资源浪费,但可以保证服务的稳定性,是一种通过牺牲资源利用率换稳定性的思想。
# 默认调度器框架
K8s 的默认调度器是 default-scheduler。它做的事情就是把 Pod 调度到合适的 Node 上,进行的操作就是将 Pod 的 spec.nodeName 字段设置为 Node 的名字。
本节介绍的是默认调度器的框架,调度算法在下一节。
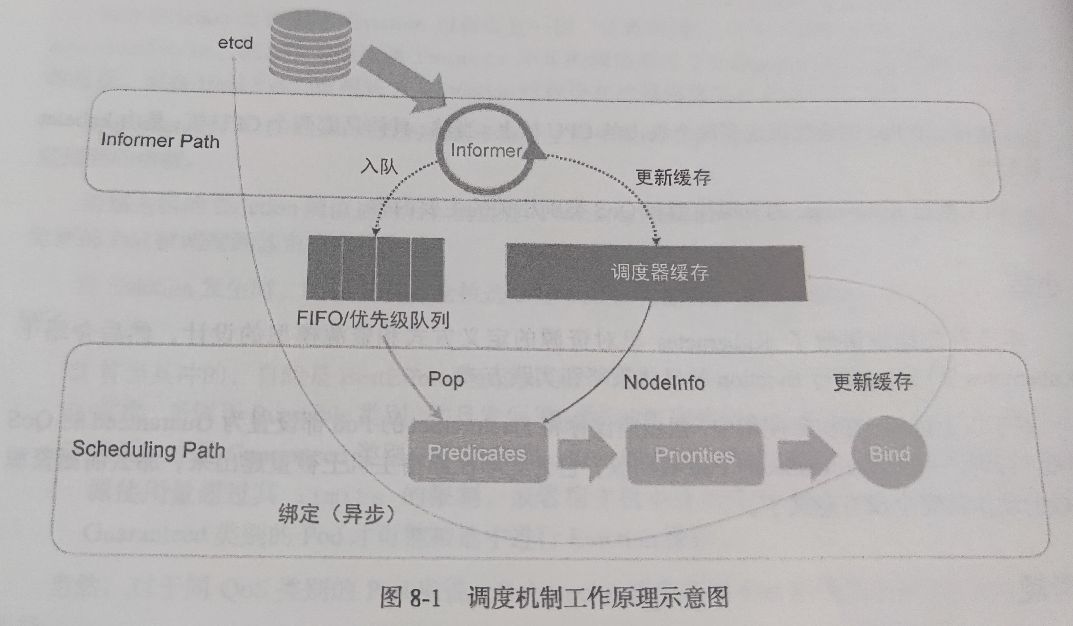
K8s 的调度步骤框架围绕着一个调度队列展开,分为两部分,一部分负责将待调度的 Pod 加入调度队列,另一部分负责从调度队列中取出 Pod 进行调度。
- 调度队列:调度队列是一个优先级队列,每个 Pod 都有一个优先级,优先级高的 Pod 会先被调度。使用优先队列而非 FIFO 主要是处于调度优先级和抢占的考虑。
- Informer Path:Informer Path 负责将待调度的 Pod 加入调度队列。Informer Path 会监听 K8s 的 API Server,当有 Pod 的状态发生变化时,Informer Path 会将 Pod 加入调度队列。除此之外,Informer Path 还会监听 Node、Service 等资源的 API,以便将集群信息缓存到本地,方便调度器使用。
- Scheduling Path:Scheduling Path 负责从调度队列中取出 Pod 进行调度。Scheduling Path 会调用调度算法,选择一个 Node,然后将 Pod 的
spec.nodeName字段设置为 Node 的名字。最后,Scheduling Path 会调用 K8s 的 API Server,将 Pod 的信息更新到 API Server 中,同时也会更新缓存。
# 调度策略
K8s 为一个 Pod 选择合适的 Node 的策略分为两步:Filter(原为 Predicates)和 Scoring(原为 Priorities)。
- Filter:Filter 是一个布尔函数,用来过滤掉不符合条件的 Node,筛选后的结果是可以运行这个 Pod 的 Node。比如,一个 Pod 需要 1G 内存,但是 Node 只有 512M 内存,那么这个 Node 就会被 Filter 函数过滤掉。Filter 函数可以有多个,每个 Filter 函数都会返回一个布尔值,只有当所有的 Filter 函数都返回 true 时,这个 Node 才会被保留下来。
- Scoring:Scoring 是一个打分函数,用来给 Node 打分,分越高表示这个 Node 越适合运行这个 Pod。比如,一个 Node 的 CPU 使用率很高,那么这个 Node 的分数就会很低。Scoring 函数可以有多个,每个 Scoring 函数都会返回一个分数,最后会将所有的分数求加权平均,得到这个 Node 的总分数。最后,调度器会选择分数最高的 Node。Scoring 函数的开关和权重可以通过为
kube-scheduler指定配置文件来修改。
K8s 的调度策略是可插拔的,可以通过配置文件来配置 Filter 和 Scoring 函数。默认的调度策略是 default-scheduler,它的 Filter 函数有 PodMatchNodeSelector、NodeAffinity、PodAffinity、PodAntiAffinity 等等,Scoring 函数有 LeastRequestedPriority、BalancedResourceAllocation、NodePreferAvoidPods 等等。
常见的 Filter (opens new window) 有:
PodMatchNodeSelector:根据 Pod 的spec.NodeSelector字段,过滤掉不符合条件的 Node。PodFitsResources:过滤掉没有足够资源的 Node。PodFitsHost:根据 Pod 的spec.NodeName字段,过滤掉不是指定 Node 的 Node。PodFitsHostPorts:过滤掉对应端口已经被使用的 Node。NoDiskConflict:过滤掉对应磁盘已经被使用的 Node。PodToleratesNodeTaints:过滤掉不符合 Pod 的spec.Tolerations字段的 Node。InterPodAffinityMatches:根据 Pod 的spec.Affinity字段,过滤掉不符合 affinity/anti-affinity 条件的 Node。
在具体执行时,调度一个 Pod 时,K8s 调度器会同时启动 16 个 Goroutine 来并发地执行 Filter 函数,最后返回符合条件的 Node。
常见的 Scoring (opens new window) 有:
- LeastRequestScorer (opens new window):选择 CPU、内存空闲最多的 Node。
- BalancedResourceScorer (opens new window):选择 CPU、内存、硬盘占用最平均的 Node。算法计算出了三种资源的占用率(request/allocatable),然后算了三个值的方差,方差越小得分越高。
- 还有
NodeAffinity、TaintToleration、InterpodAffinity的 Scoring 算法,满足条件的 Node 得分会更高。
# 调度中的抢占机制
正常情况下,Node 资源不足时,Pod 会被“搁置”,直到资源足够时再调度。但是有时候,我们希望某些 Pod 能够优先调度,比如重要的服务、紧急的任务等等。这时候就需要抢占机制。
K8s 的抢占机制,可以在 Node 资源不足时,优先调度高优先级的 Pod。抢占机制的实现是通过杀掉一些低优先级的 Pod,释放资源。
定义 Pod 的优先级,需要先定义一个 PriorityClass 对象,然后在 Pod 的 spec.priorityClassName 字段指定这个优先级。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
------
apiVersion: v1
kind: Pod
metadata:
name: high-priority-pod
spec:
priorityClassName: high-priority
containers:
- name: high-priority-container
image: nginx
Kubernetes 的抢占机制的实现,用到了两个队列,一个是 activeQ,另一个是 unschedulableQ。
- activeQ 就是下个调度周期要调度的 Pod 队列。所以在创建了一个 Pod 对象后,会先加入 activeQ。调度器也是从 activeQ 里面 pop Pod 对象,然后进行调度。
- unschedulableQ 是调度器调度失败的 Pod 队列。在 Pod 进入 unschedulableQ 以后,如果 Pod 对象发生了更新,这个 Pod 会被重新移动到 activeQ 中。
当高优先级的抢占者 Pod 第一次调度失败后,被挪到 unschedulableQ 后,就会触发调度器为抢占者寻找低优先级的牺牲者 Pod。这个寻找过程是一个模拟算法,模拟把节点里低优先级 Pod 逐一删除,然后检查抢占者是否可以运行。模拟算法会从抢占结果中选择一个最好的(对系统影响最小的,比如抢占的 Pod 数少、优先级低)。然后就会执行抢占操作:
- 清理牺牲者 Pod 的
nominatedNodeName字段。调度器使用nominatedNodeName字段来跟踪为 Pod 保留的资源,同时也向用户提供与集群中抢占相关的信息。 - 把抢占者 Pod 的
nominatedNodeName字段设置为牺牲者的 Node 名字。由于 Pod 信息更新,调度器会把抢占者 Pod 重新加入 activeQ。 - 遍历牺牲者列表,向 API Server 请求删除这些 Pod。
然后,调度器会再次调度抢占者 Pod。不过,调度器并不保证这次一定会成功,因为在这个过程中,可能又有新的 Pod 进入 activeQ,导致资源不足。
除了上述核心机制以外,还有一些特殊情况需要单独处理。
在为一个 Pod 和 Node 执行 Filter 算法时,如果满足①待检查的 Node 即将被抢占(即 activeQ 存在一个 Pod,这个 Pod 的 nominatedNodeName 为该 Node)②抢占者 Pod 的优先级高于或等于待检查的 Pod。为了防止当前 Pod 分配上去后又立即被抢占,会执行两遍 Filter 算法。第一遍检查如果抢占者已经在该节点上运行的情况,第二遍按照正常情况进行检查,即不考虑抢占者运行在该 Node 上运行的情况。最后把两个算法的结果取 and,如果结果为 false,就不会把 Pod 分配到该 Node 上。
# 容器运行时
在 Kubernetes 1.6 之前,K8s 直接调用 Docker 的 API 来管理容器。但随着容器技术的发展,K8s 也需要支持更多的容器运行时,比如 rkt、runV(runV 还是基于虚拟化技术的容器,导致 K8s 适配的工作更加复杂)等等,K8s 的维护工作越来越大。所以在 1.6 版本引入了 CRI(Container Runtime Interface,容器运行时接口)来解耦 K8s 和容器运行时。解耦以后,K8s 只需要支持 CRI,而不需要支持具体的容器运行时;容器运行时只需要适配 CRI,就可以和 K8s 通信了,节省了两边的维护成本。
容器运行时适配 CRI 的这一层被称为 CRI shim(CRI 垫片),比如 Docker 的 shim 叫做 dockershim。
# CRI
CRI shim 需要实现两个服务:RuntimeService 和 ImageService。RuntimeService 主要负责容器的生命周期管理,比如创建、销毁容器;ImageService 主要负责镜像的管理,比如拉取、删除镜像。
// https://github.com/kubernetes/cri-api/blob/master/pkg/apis/runtime/v1/api.proto
service RuntimeService {
rpc Version(VersionRequest) returns (VersionResponse) {}
rpc RunPodSandbox(RunPodSandboxRequest) returns (RunPodSandboxResponse) {}
rpc StopPodSandbox(StopPodSandboxRequest) returns (StopPodSandboxResponse) {}
rpc RemovePodSandbox(RemovePodSandboxRequest) returns (RemovePodSandboxResponse) {}
rpc PodSandboxStatus(PodSandboxStatusRequest) returns (PodSandboxStatusResponse) {}
rpc ListPodSandbox(ListPodSandboxRequest) returns (ListPodSandboxResponse) {}
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {}
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {}
rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse) {}
rpc ListContainers(ListContainersRequest) returns (ListContainersResponse) {}
rpc ContainerStatus(ContainerStatusRequest) returns (ContainerStatusResponse) {}
rpc UpdateContainerResources(UpdateContainerResourcesRequest) returns (UpdateContainerResourcesResponse) {}
rpc ReopenContainerLog(ReopenContainerLogRequest) returns (ReopenContainerLogResponse) {}
rpc ExecSync(ExecSyncRequest) returns (ExecSyncResponse) {}
rpc Exec(ExecRequest) returns (ExecResponse) {}
rpc Attach(AttachRequest) returns (AttachResponse) {}
rpc PortForward(PortForwardRequest) returns (PortForwardResponse) {}
rpc ContainerStats(ContainerStatsRequest) returns (ContainerStatsResponse) {}
rpc ListContainerStats(ListContainerStatsRequest) returns (ListContainerStatsResponse) {}
rpc PodSandboxStats(PodSandboxStatsRequest) returns (PodSandboxStatsResponse) {}
rpc ListPodSandboxStats(ListPodSandboxStatsRequest) returns (ListPodSandboxStatsResponse) {}
// ...
}
service ImageService {
rpc ListImages(ListImagesRequest) returns (ListImagesResponse) {}
rpc ImageStatus(ImageStatusRequest) returns (ImageStatusResponse) {}
rpc PullImage(PullImageRequest) returns (PullImageResponse) {}
rpc RemoveImage(RemoveImageRequest) returns (RemoveImageResponse) {}
rpc ImageFsInfo(ImageFsInfoRequest) returns (ImageFsInfoResponse) {}
}
# 安全容器
本书还聊到了两个安全容器的技术,一个是 Kata Containers,一个是 gVisor。
Kata Containers 是一个基于虚拟化技术的安全容器,它会使用虚拟机管理程序(VMM,比如 Qemu)为每个 Pod 创建一个虚拟机,这样就可以隔离容器之间的网络、内存、磁盘等资源。Kata Containers 的优点是安全性高,缺点是性能差,因为每个容器都需要一个虚拟机。
而 gVisor 就激进多了,它为容器启动了一个 Sentry 进程,这个进程负责提供一个操作系统内核的能力:运行用户进程,执行系统调用。所以它相当于在模拟一个系统内核。gVisor 的优点是性能高,缺点是很多 Linux 系统调用都还不支持,所以不是所有的应用都能跑在 gVisor 里。
# 监控
K8s 相关监控现在都是通过 Prometheus 来做的。之前配置 Prometheus + Grafana 的经验写在这篇博客 了,这里简单摘抄一段架构。
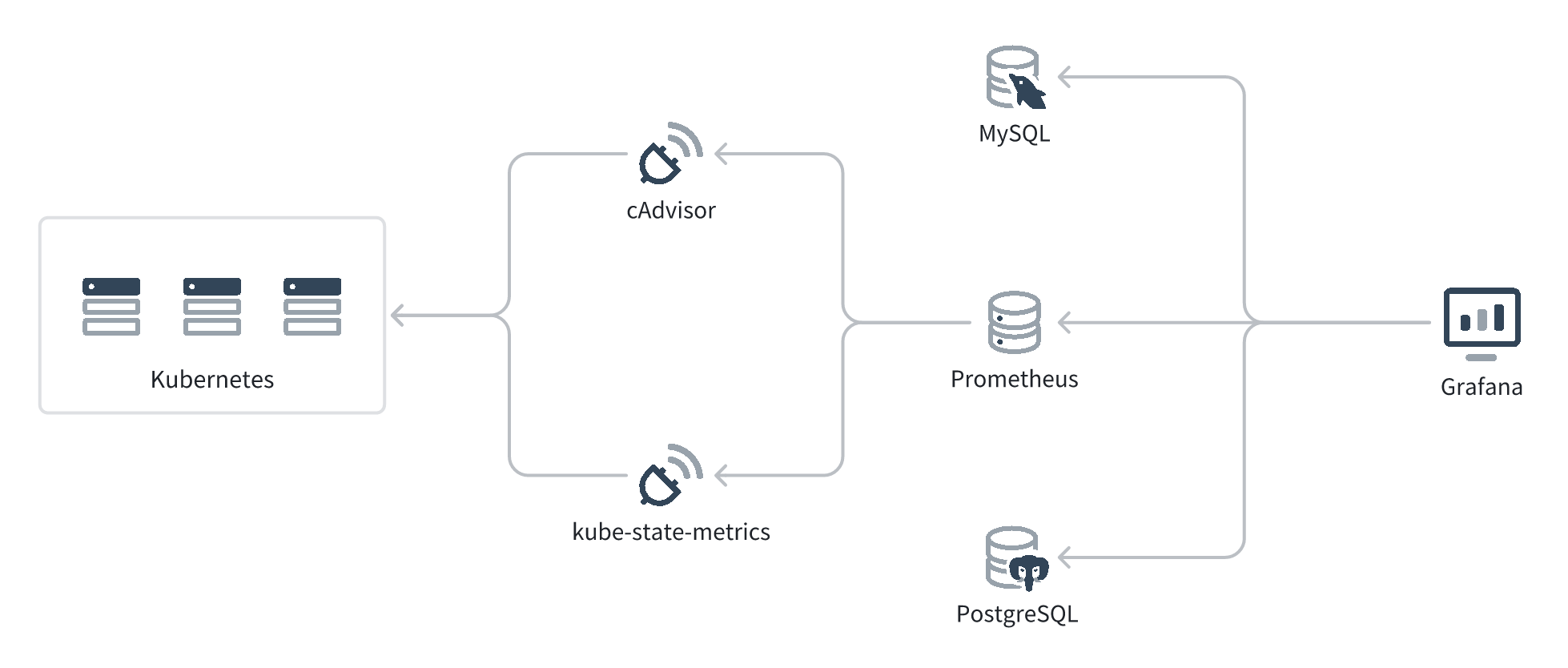
- cAdvisor (opens new window) 和 kube-state-metrics (opens new window) 会作为 Kubernetes Daemonset 运行在 Kubernetes 的每个 Node 上,通过 Kubernetes API 收集 Node、Pod 等的实时指标,然后转换成 Prometheus 能理解的数据结构,通过 HTTP API 暴露出来。cAdvisor 和 kube-state-metrics 收集的数据有一些互补,所以推荐两个都部署。
- Prometheus 会定时拉取 cAdvisor 和 kube-state-metrics 的数据,然后存储到自己的时间序列数据库中。
- Grafana 不会持久化 metric 数据,而是持久化图表的配置,然后通过 PromQL 从 Prometheus 查询数据、展示出来。Grafana 也支持通过 SQL 和其它查询语法从 MySQL、PostgreSQL 等数据源查询数据。
# 日志
K8s 日志收集的几个方案:
- 如果应用将日志输出到 stdout 和 stderr,宿主机会将这些日志收集到
/var/log/pods/<namespace>_<pod_name>_<pod_id>/<container_name>/<container_id>.log文件中。只需要部署一个 logging-agent 的 daemonset,比如 Fluentd 或者 Filebeat,就可以将这些日志收集到中心化的地方,比如 ELK 或者 Loki。这个方案的优点是简单、对代码和 Pod 配置都没有侵入性,缺点是要求容器将日志输出到 stdout 和 stderr。这应该是最常用的方案。 - 如果应用将日输出到文件,可以通过 sidecar 容器将文件重新输出到 stdout 和 stderr(比如
tail -f file.log),然后按照方案 1 收集。这个方案的优点是无需修改应用,缺点是需要修改 Pod 的配置,增加 sidecar 容器,以及日志会占两倍空间,一倍在应用的输出,一倍在宿主机的 log 目录下。 - 如果应用将日志输出到文件,还可以通过 sidecar 容器将这些日志直接收集到中心化的地方。相较于方案二,这个方案的优点是不会占用两倍空间。
- 如果应用层有日志收集的 SDK,可以直接将日志发送到中心化的地方。这个方案就是让应用层处理日志收集,而非在 K8s 层做了,适合于已经有日志收集 SDK 的大公司。这个方案的优点是适用于任何环境的部署,缺点是对代码有侵入性。