本篇是《深入剖析 Kubernetes》 的读书笔记,作者为张磊老师。
本章讲述了 Kubernetes 的网络模型,会相较于 Pod、存储章更难一些,且需要有一定的计算机网络的知识作为前置。
# 单机容器网络架构
在单机容器网络架构中,容器和宿主机、容器和容器之间的通信,需要借助两样东西,一是网桥(Bridge),二是虚拟网卡(Veth Pair, Veth = Virtual ethernet)。
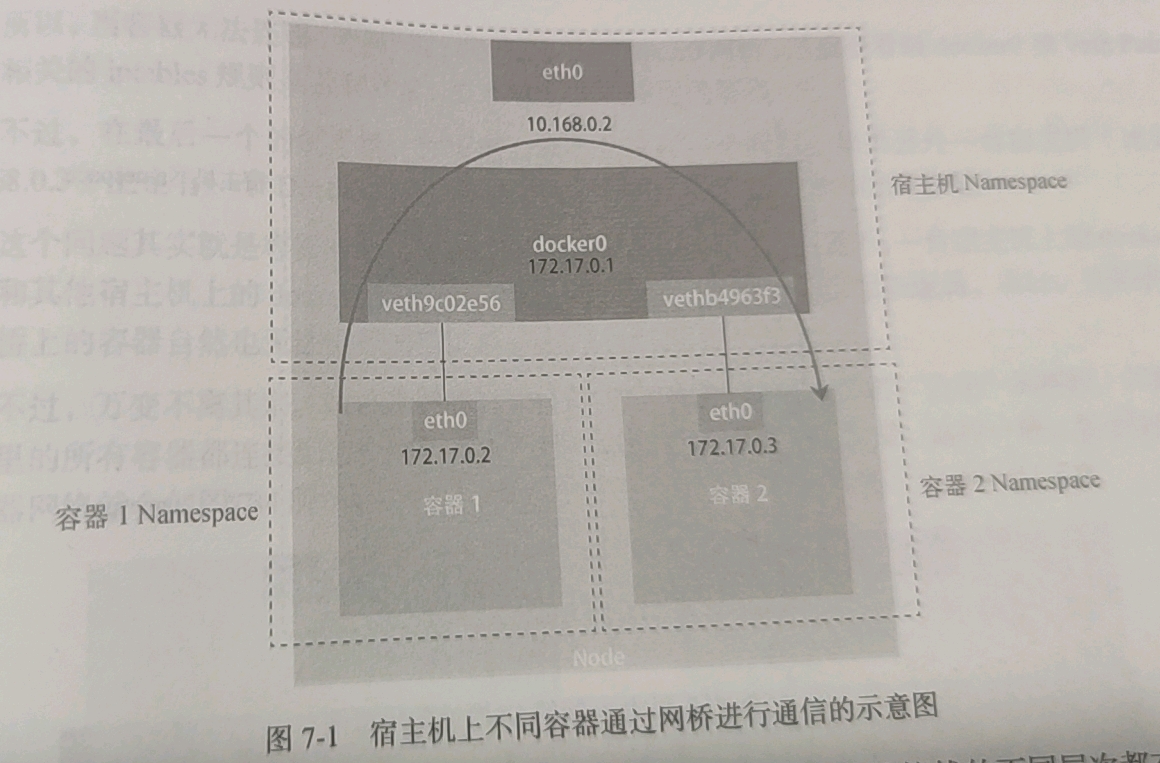
Docker 会在宿主机上创建一个名为 docker0 的网桥。只要容器连接到这个网桥,就可以和宿主机上的其它容器通信。
容器连接到网桥的方式是 Veth Pair。Veth Pair 是一对虚拟网卡,一端连接到 docker0,一端连接到容器,就可以将二者连通,即使二者不在一个 Namespace 下也可以连通。每创建一个容器,Docker 就会在网桥上创建一对 Veth Pair,将容器和 docker0 连接起来。
容器和宿主机连起来了以后,容器之间的通信是怎么实现的呢?这就要提到网桥的转发机制了。当一个虚拟网卡被插到网桥后,它就会变成网桥的“从设备”,流入的数据包会交给网桥处理。网桥会扮演二层交换机的角色,根据数据包的目的 MAC 地址,将数据包转发给宿主机或者容器对应的虚拟网卡。
# 多机容器网络架构
# Flannel
多机容器间的通信使用的是 Flannel 网络方案。Flannel 是一个简单且高效的网络解决方案,通过子网和路由表来实现容器间的通信。
所有 Node 在一个子网下(如 100.96.0.0/16),每个 Node 上的所有容器在 docker0 这个更小的子网里(如100.96.1.0/24)。Flannel 在 Node 上会创建这样路由表:
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.1.0
100.96.1.0/24 dev docker0 proto kernel scope link src 100.96.1.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.2
flannel0 是 UDP 方案所使用的 TUN 设备,其它方案会用别的设备名,但是原理都是将所有 Node 放在一个大的子网下。
由于路由时会用最长匹配原则,所以当容器要访问同一个 Node 上的容器时,会走 100.96.1.0/24 docker0 的路由表;当要访问其它 Node 上的容器时,会走 flannel0 的路由表,发给其它 Node,然后再由这个 Node 发给 docker0。
# Flannel 的后端实现
Flannel 的方案里,真正为我们提供通信,把发往 Flannel 的包发送给其它 Node 的,是 Flannel 的后端实现。
Flannel 有多种后端实现,如 VXLAN、Host-GW、UDP 等。
# UDP
UDP 是最简单、最好理解的,也是性能最烂的,所以现在已经被弃用了。
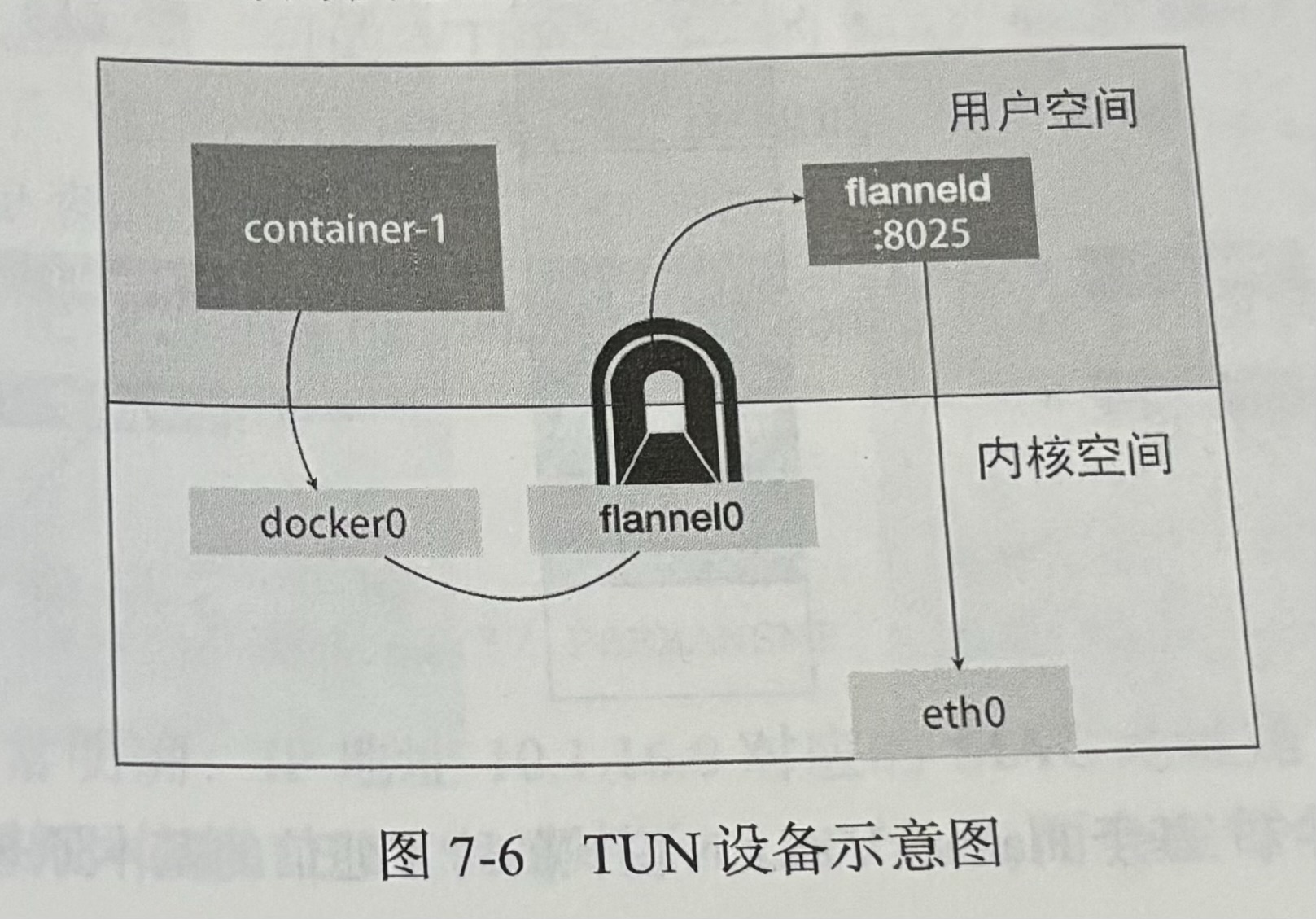
UDP 方案基于 TUN 设备 (opens new window)。这个设备是一个在三层(网络层)工作的虚拟网络设备。其功能是:在操作系统和用户应用程序之间传递 IP 包。TUN 设备可以说是系统内核和用户空间之间的一个隧道。
Flannel 会在每个 Node 上启动一个代理进程 flanneld,监听一个 UDP 端口(通常是 8025),用于接收其它 Node 发来的包。Node1 的 flannel0 收到一个 IP 包以后,会通过 TUN 设备转发给 flanneld 进程。flanneld 把这个 IP 包封在一个 UDP 包里,然后发给目标 Node 的 8025 端口。
这个方案很好理解,但是性能瓶颈在于数据在内核空间和用户空间之间进行了反复拷贝。在发出过程中,就进行了 3 次复制。
# VXLAN
VXLAN 是目前最常用的 Flannel 后端实现。
VXLAN 方案基于 VXLAN 技术 (opens new window),它负责在两个节点之间建立一个隧道,将二层数据帧封装在 UDP 包里(L2 over L4),然后通过这个隧道传输。
VXLAN 这个隧道两端的接口设备是 VTEP,Flannel 把这个设备命名为 flannel.1(而非 flannel0),它负责对数据帧进行封装和解封装,而且这个工作是在内核里完成的(因为 VLAN 是 Linux 内核里的一个模块),所以性能比 UDP 方案要好。
所以其实 VXLAN 方案和 UDP 方案的架构其实差不多,都是在两个宿主机之间建立一个隧道,负责传递跨机容器的 IP 包。VXLAN 主要赢在 VXLAN 是内核模块,不需要在内核空间和用户空间之间进行数据拷贝。
# Host-GW
Host-GW 是 Flannel 的另一个后端实现,它是性能最好的方案,但要求所有 Node 二层连通。
Host-GW 的意思是通过配置路由表,把宿主机(Host)当做网关(Gateway)。这样,宿主机之间不需要建立隧道,也不需要将 IP 包封装在 UDP 包里,只需要通过路由表,将 IP 包直接发给目标宿主机,免除了封装和解封装的性能损耗。
在公有云上,由于网络结构简单,Host-GW 是最好的选择。
# Calico
Calico 是另一个三层网络方案,这个方案复杂很多,实现也更加重量级,但也能应对更复杂的网络环境,是这个领域的“龙头老大”。
和 Flannel 的 Host-GW 类似,Calico 同样是让宿主机作为网关。但不同于 Flannel 通过 etcd 和宿主机上的 flanneld 维护路由信息的做法,Calico 通过 BGP 协议来维护路由信息。
Calico 的工作原理是:在每个 Node 上创建一个 BGP 路由器,然后通过 BGP 协议,将容器的 IP 地址告诉其它 Node。这样,每个 Node 都知道其它 Node 上的容器的 IP 地址,就可以直接通信了。
死去的计算机网络开始攻击我
为了解决不同子网的宿主机之间的通信,Calico 引入了几种方案。
- IPIP 模式:类似于 UDP 和 VXLAN,在两个宿主机之间建立隧道。但不同于 UDP 和 VXLAN 建立的 UDP 隧道,IPIP 建立的是 IP 隧道。原始 IP 包进入隧道后,会在头部加上一个新的 IP 报头,封装为一个新的 IP(IP over IP),然后再发出去。这样,就可以实现不同子网的宿主机之间的通信。但这个方案的性能和 VXLAN 差不多,因为也需要封包、解包。
- 在所有宿主机和宿主机网关之间建立 BGP Peer 关系。
- 使用一个或多个独立组件,负责收集整个集群的路由信息,然后通过 BGP 协议同步给网关。
后两种方案的性能很好,不过需要做额外的配置,会麻烦一些。
# Flannel 的三种方案和 Calico 的对比
| 方案 | UDP | VXLAN | Host-GW | Calico |
|---|---|---|---|---|
| 工作层数 | 四层(UDP) | 四层(UDP) | 三层(IP) | 三层(IP) |
| 工作环境 | 三层连通 | 三层连通 | 二层连通 | 二层连通,或在不同子网中 |
| 性能 | 差 | 中 | 好 | 好 |
| 复杂程度 | 简单 | 简单 | 简单 | 复杂 |
| 适用场景 | 无 | 小规模快速部署 | 公有云 | 私有云 |
# Kubernetes 网络模型
Kubernetes 的网络模型其实和上面所讲的“多机容器网络架构”非常相似,只不过 Kubernetes 为了支持多种网络方案,引入了 CNI 插件,Flannel 是 Kubernetes 内置的 CNI 插件。还有一点不同的是,Kubernetes 使用的网桥叫 cni0,而非 docker0。这也合理,因为 Kubernetes 里的容器不一定是 Docker。
# CNI 插件
容器内网络初始化的调用链:CRI 实现(如 dockershim) -> Pod 的 Infra 容器 -> CNI 插件(如 Flannel) -> CNI Bridge 或其它网络设备的可执行文件。
CNI 插件的配置是在宿主机的 /etc/cni/net.d 目录下,安装 Flanneld 时会在每台宿主机上创建一个 /etc/cni/net.d/10-flannel.conflist。
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
通过这个配置文件,Infra 容器就会依次调用 flannel 和 portmap 这两个插件,完成容器网络的初始化。
而 flannel 配置了 delegate,表示它会将网络的初始化委托给其它插件完成。在委托之前,flannel 会对配置进行补全。补全后的 delegate 配置如下:
{
"hairpinMode": true,
"isDefaultGateway": true,
"name": "cbr0",
"type": "bridge",
"isGateway": true,
"ipMasq": false,
"ipam": {
"type": "host-local",
"subnet": "10.244.1.0/24",
"routes": [
{
"dst": "10.244.0.0/16"
}
]
},
"mtu": 1410
}
从补全的配置可以看到,flannel 将委托 bridge 插件完成网络初始化。它会创建一个 cni0 的网桥(如果宿主机上已经有了就跳过),然后将容器连接到这个网桥。
# Kubernetes 中的网络隔离:NetworkPolicy
上面都在说如何让容器之间连通,这里来说一下如何让容器之间不连通。
从直觉上来说,相较于“让容器连通”,“让容器不连通”会更简单,因为只需要让用户声明一些规则,然后用这些规则来过滤数据包就行了。Kubernetes 也是这么做的,让用户声明 NetworkPolicy 这样的规则,然后让网络插件(Calico、kube-router)等实现这些规则。
NetworkPolicy 是一个 Kubernetes 的资源对象,它定义了一组规则,这些规则决定了哪些 Pod 之间可以通信,哪些 Pod 之间不能通信。
一条 NetworkPolicy 的内容分为三部分:
podSelector:选择器,选择哪些 Pod 会受到这个 NetworkPolicy 的影响。在 Pod 没有被选择的情况下,Pod 默认可以进行任何通信;Pod 被选择后,Pod 默认不能通信,只有符合 NetworkPolicy 的规则才能通信。ingress:入口规则,定义了允许哪些 Pod 访问这些 Pod。egress:出口规则,定义了这些 Pod 可以访问哪些 Pod。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
# 控制 role=db 的 Pod
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
# ingress:流入 Pod 的流量
ingress:
- from:
# role=db 的 Pod 可以从符合这三种条件之一的 Pod 接收入口流量
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
# role=db 的 Pod 可以向这个 IP 段的 Pod 发送出口流量
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
三层插件(如 Calico 和 kue-router)对 NetworkPolicy 的实现原理是:在每个 Node 上,为每个 Pod 都创建一个 iptables 规则,根据 NetworkPolicy 的规则,对数据包进行过滤。
# 将所有 Pod 的流量从正常流量都“拦截”到 FORWARD 链中,跳转到 KUBE-POD-SPECIFIC-FW-CHAIN 规则
for pod := range 该 Node 上的所有 Pod {
if pod 是 networkPolicy.spec.podSelector 选中的 {
# 拦截同宿主机容器通过网桥发的包
iptables -A FORWARD -s $podIP -m physdev --physdev-is-bridged -j KUBE-POD-SPECIFIC-FW-CHAIN
# 拦截跨主机容器发的包
iptables -A FORWARD -d $podIP -j KUBE-POD-SPECIFIC-FW-CHAIN
}
}
# 将 KUBE-POD-SPECIFIC-FW-CHAIN 规则中的包跳转到 KUBE-NWPLCY-CHAIN 规则。如果跳转后没有匹配到结果,则拒绝包
iptables -A KUBE-POD-SPECIFIC-FW-CHAIN -j KUBE-NWPLCY-CHAIN
iptables -A KUBE-POD-SPECIFIC-FW-CHAIN -j REJECT --reject-with icmp-port-unreachable
for dstIP := range 所有被 networkPolicy.spec.podSelector 选中的 Pod 的 IP 地址 {
for srcIP := range 所有被 ingress.from.podSelector 选中的 Pod 的 IP 地址 {
for port, protocol := range ingress.ports {
# 允许 KUBE-NWPLCY-CHAIN 规则中,符合条件的包通过
iptables -A KUBE-NWPLCY-CHAIN -s $srcIP -d $dstIP -p $protocol -m $protocol --dport $port -j ACCEPT
}
}
从上面的伪代码可以看到,Kubernetes 的 NetworkPolicy 是通过 FORWARD、KUBE-POD-SPECIFIC-FW-CHAIN、KUBE-NWPLCY-CHAIN 这条规则链实现的。
真是简单粗暴的实现。这也说明 iptables 是一个非常强大的工具。
# Service 的实现
Kubernetes 的 Service 是用于负载均衡的,它可以将一组 Pod 封装成一个服务,然后通过 Service 的 ClusterIP、NodePort、LoadBalancer 等类型,将这个服务暴露出去。
Service 的实现原理是:Worker 结点上的 kube-proxy 监听 Service 对象,然后生成对应的 iptables 规则,将流量转发到对应的 Pod 上。
iptables -A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/my-service:clusterIP" -m tcp --dport 80 -j KUBE-SVC-ABCDEF1234
iptables -A KUBE-SVC-ABCDEF1234 -m comment --comment "default/my-service:clusterIP" -m statistic --mode random --probability 0.3333333333 -j KUBE-SEP-ABCDEF1234
iptables -A KUBE-SVC-ABCDEF1234 -m comment --comment "default/my-service:clusterIP" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-ABCDEF5678
iptables -A KUBE-SVC-ABCDEF1234 -m comment --comment "default/my-service:clusterIP" -j KUBE-SEP-ABCDEF9012
iptables -A KUBE-SEP-ABCDEF1234 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
iptables -A KUBE-SEP-ABCDEF5678 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
iptables -A KUBE-SEP-ABCDEF9012 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
这个规则的意思是:当有流量发往 10.0.1.175/32 的这个 Service IP 时,会根据 KUBE-SVC-ABCDEF1234 这个规则链,随机转发到 KUBE-SEP-ABCDEF1234、KUBE-SEP-ABCDEF5678、KUBE-SEP-ABCDEF9012 这三个 Pod 上。需要注意的是,iptables 规则的匹配是从上到下逐条执行的,所以为了保证 3 条规则每条规则的流量占比都是 1/3,我们应该将 probability 设置为 1/3、1/2、1,即以 1/3 的概率命中第一条,剩下的情况里再以 1/2 的概率命中第二条,如果都没命中就命中第三条。
基于 iptables 的实现在大的 Worker 节点上可能会有性能问题。每个 Service 的 Pod 都有对应的 iptables 规则,流量到达 Pod 之前会经过很多规则,影响整体性能(NetworkPolicy 虽然也是基于 iptables,但它的规则比较简单,只是允许或拒绝某些流量)。所以诞生了 IPVS 这个更高效的实现。
IPVS 模式的工作原理和 iptables 类似。
- 创建 Service 以后,kube-proxy 会在 Worker 节点上创建一个 IPVS 的虚拟网卡,并将 Service VIP 分配给它作为 IP 地址。
- 然后 kube-proxy 会为每个 Pod 创建一个 IPVS 的 EndPoint,将 Pod 的 IP 地址和端口映射到这个 EndPoint 上。
虽然 IPVS 在内核中的实现和 iptables 一样基于 Netfilter 的 NAT 模式,但它不需要维护 iptables 规则链,而是把这些放在内核态里处理,所以性能更好。
# Ingress 对象
这里说的不是 NetworkPolicy 对象里的 ingress 字段,而是 Ingress 对象,两者是不同的。
Kubernetes 的 Ingress 对象是一个全局的负载均衡器,负责将外部流量转发到集群内部的 Service 上。其实 Ingress 起到的作用和平时单机部署时使用的 Nginx 很相似,这么类比一下就很好理解 Ingress 了。实际上,Kubernetes 的 Ingress Controller 的其中一种实现,就是基于 Nginx 的。
所以 Ingress 能配置的东西也和 Nginx 类似,比如:反向代理、负载均衡、SSL、基于 URL 的路由等。