书里讲的很多例子其实已经有些老生常谈了,在九年义务教育和高中、大学中已经被拿出来鞭尸过很多次了(例如使用平均数、中位数和众数来描述一个公司的工资水平)。在互联网发达的今天,会有嘴替替我们指出数据里的问题。
以及,这本书否定了很多错误的统计数据,但没有告诉我们什么是正确的统计数据。正确的统计数据,还是需要培养常识来判断,那些明显偏离自己常识的,数据可能会有问题。
总的来说,这本书在过去是一本好书,但现在可能有些过时了。
# 第一章:内在有偏的样本
主要讲各种样本的偏差。在各类调查问卷中,选择一个合适的样本会直接关系到结果的准确性,但这真的很难。
民意调查最终将演变为一场与误差的遭遇战。所有信誉良好的调查公司将不可避免地投入到这场战斗中。
# 第二章:精心挑选的平均数
注:原作将算术平均数、中位数、众数统称为“平均数”,所以书里提到“平均数”时会去质疑这个平均数是哪种平均数。
当看到某些人平均身高为5英尺时,你便能对这些人的外形有大概的了解,而根本不需过问这个平均数到底是均值、中位数还是众数,因为它们没有过多的区别。因为这些数据的分布十分接近正态分布,而正态分布的均值、中位数和众数是相等的。
在描述他们的经济收入时,却不是那么回事了。
身高遵守正态分布,而收入遵二八法则(也称帕累托法则)。
# 第三章:没有披露的数据
样本过小产生的随机性,使得数据可能会“出奇的好”。而随机更坏的数据被隐藏起来了。
没有注解的图表没有意义。能被任意解读。
# 第四章:毫无意义的工作
无论智力测验测试什么内容。它都与我们平常意义上的智商相去甚远。它忽略了类似领导才能、创造性想象力等十分重要的素质;它没有考虑到社交判断力以及音乐、艺术或其他方面的才能;它无法测试出诸如勤劳、情感平衡等重要的人格品质。再加上,大部分学校做的智力测试都是简单低廉的类型,它们极大程度地依赖于阅读能力、测验者反映的快慢等因素,阅读速度慢的人根本没有拿高分的希望。假设我们对这些都有了重新认识并一致达成共识:智力测验仅仅测验了处理那些预先准备好的抽象问题的能力,而这些能力又很难确切地进行定义。
有些时候两个测量结果的差距甚至小于测量误差,这样的两个测量结果是不可比较的。
# 第五章:惊人的统计图形
画统计图的欺骗技巧。
改变横轴与纵轴刻度的比例关系,将纵轴的每一个刻度缩减为原来的1/10,斜率就会变为10倍。反之也可以以数倍缩小斜率。下面的图看着斜率差距很大,但实际上是一样的。
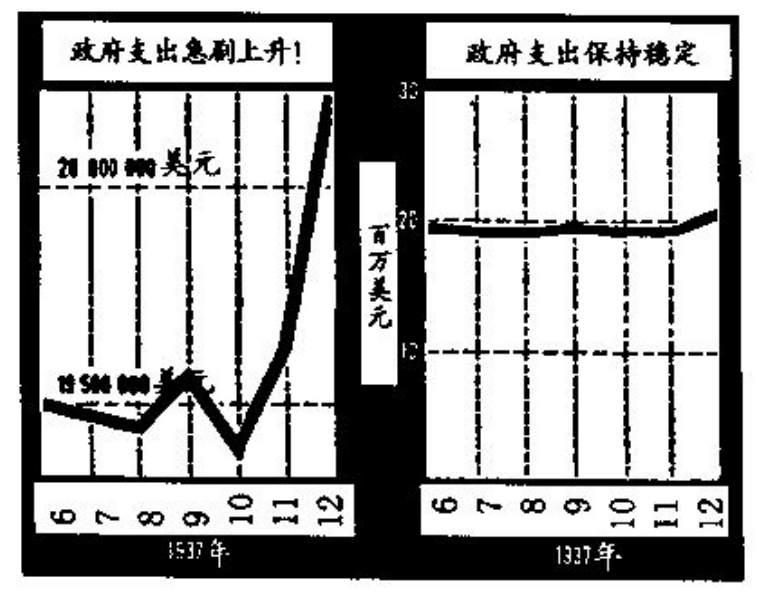
# 第六章:平面图形
用一个小人来表示成千上万的人,一个钱袋或一堆硬币表示成千上万的钱,一片牛肉来表示明年牛肉的供应量,这些都是形象化的图形。由于十分吸引人,它可以作为一种有用的工具,但同时它也能摇身一变,成为一个老练、狡猾而且成功的骗子。

# 第七章:不相匹配的资料
这章讲的是证据正确、但推理错误,导致错误结论的情况。
以同样荒谬的逻辑继续推理下去的话,你还可以证明天气晴朗时驾车比有雾时更危险。因为晴天比雾天多,所以天气晴朗时会有更多的交通意外。但只要运用常识,你我都能知道雾会使驾车变得危险。
“去年飞机失事造成的人员死亡比1910年多”,这是否意味着现在乘飞机要比过去危险?认为更危险的说法是不合理的,因为选择飞机作为交通工具的人已经是以前的几百倍了。
这是一个有趣的事实,在考虑某种疾病的发病情况时,使用死亡率或者死亡人数比发病人数更合理——这是因为死亡报道和死亡记录的质量更高。
来一道阅读理解:
1942年杜威(Dewey)当选州长时,一些地区教师的最低年收入只有900美元;今天,而纽约州的教师享有全世界最高的收入水平。在杜威政府的建议下,在由杜威指定的委员会的表决下,立法机构于1947年从州财政盈余中拨出3200万美元直用于提高教师收入水平,这使得纽约市教师最低收入水平提高到2500~5323 美元之间波动。
上面这段话有什么问题?
也许,杜威先生想借此表明自己是教师的朋友,但是这些数据并不能证明这一点。这里使用了前后比较的老把戏,一些没有指明的因素加入到过程中,导致前后并不一致。以前只有900美元,而现在是2500~5325美元,的确有了长足的进步。但实际上,前者是该州乡村地区的最低收入,而后者仅仅是纽约市的最低收入水平。这些进步只能部分归功于杜威政府。
# 第八章:相关关系与因果关系
这章讲的东西已经写标题里了。相信本文的读者也清楚这一点,相关关系≠因果关系。
即使是相关关系本身,在没有足够的数据证明之前,可能也是不可信的。很多数据的变化是随着时代变化的,而不是数据之间可能存在相关性。比如使用 20 年前和现在的香烟消费数据,得出 “国内经济越发达,抽烟的人越多” 的结论显然是不合理的。
当你发现某些人在胡乱使用相关性时,请注意分辨相关是否是事件变迁的产物或时代趋势的产物。在我们这个时代的任何一对数据,例如大学生的人数、心理研究机构同房间的病人数、香烟的消费量、心脏病的发病率、X光的使用次数、假牙的生产量、加利福尼亚学校老师的薪水、内华达州赌博的利润等,都很容易显示出正相关关系。
# 第九章:如何进行统计操纵
统计操纵:利用统计资料传递错误的信息而误导他人可称得上是一种操纵行为。
这段里举了非常多的例子,包括上面已有的一些例子,以及对百分比直接进行加减乘除得出的具有误导性的结论,等等。
# 第十章:对统计资料提出的五个问题
总结性章节
- 谁说的?(是否是利益相关者?是权威人士说的,还是仅仅和权威人士沾边?)
- 他是如何知道的?(调查过程是否有偏?调查量是否够大?他的分析基于的数据是否是有偏的?)
通常,你无法了解样本包含了多少案例。这个数据的缺失,特别当信息的来源存在着利害关系时,已足以使你对整件事情提出质疑。
- 是否有人偷换了概念?
- 这个资料有意义吗?