该篇博客为肖鸣宇老师所开的 Design and Analysis of Algorithms 课程的笔记。
# 绪论
# 算法解决的三种问题
- Desicion Problem(判断是否)
- Optimal(最优化的结果/解)
- Numeric Calculation(数字计算、解方程)
# 问题的分类(按复杂度)
- P: a solutuon can be solved in polynimoal time.
- NP: a solution can be checked in polynomial time.
- NPC: problems that may not have a polynomial-time algorithm.

- PTAS: Polynomial-time approximation scheme
和上面不同的是,上面的词描述的都是问题,而 PTAS 是解决问题的方法。也就是说,可以说某个 NP-Hard 问题有 PTAS 算法。
PTAS 要求对于给定的任意近似率 1+\varepsilon,都能给出一个多项式算法,虽然这个多项式在 \varepsilon 趋于 0 时会变为指数级或更高。一般来说 PTAS 算法的复杂度都可以写为 或 。如 TSP 问题和背包问题都存在 PTAS 算法。
# NPC 问题的求解
- 启发式算法(Heuristic algorithm):我觉得怎么好,就怎么做。不知道对不对,但是跑的确实快。例如:人工智能方面。
- 近似算法(Approximation Algorithm):在多项式时间内得到一个近似解。(难点在于证明近似)
- 快速算法:高效的指数运行时间的精确算法。
- 参数算法:参数小的时候,能高效解决问题。近年来兴起。
# 稳定婚姻问题 Stable Match / Stable marriage problem
给定 n 男 n 女,以及每个人对异性对象的喜好程度(按 1 至 n 排列)。安排男女结婚,使得不出现以下不稳定情形:
在 n 男 n 女中的存在两对夫妇 (M, W) 和 (m, w),M 男对 w 女喜好度大于现任妻子 W 女,并且 w 女对 M 男喜好度也大于现任丈夫 m 男。
找到解、证明其符合题意、证明是否存在最优解都不是很显然。
# 稳定室友问题 可能无解
若给 2n 个人,可以随意选择其他 2n-1 人。可能无解。如下图:

# Gale-Shapley 算法
Gale-Shapley 算法,1962
Initialize each person to be free.
while (some man is free and hasn't proposed to every woman)
{
Choose such a man m
w = 1st woman on m's list to whom m has not yet proposed
if (w is free)
assign m and w to be engaged
else if (w prefers m to her fiancé m')
assign m and w to be engaged, and m' to be free
else
w rejects m
}
# 正确性证明:终止
注意到:
(1) 男生从高到低求婚,且对同一个女生只会求一次婚; (2) 女生一脱单,不会重返单身;
因此,由 (1),最多进行 次匹配后,程序会终止。
# 正确性证明:所有人都被匹配
数学三大证明方法:反证、归纳、构造。
反证(By Contradiction):不妨设(Suppose, for sake of contradiction, that)结束时 Zeus 没有被匹配,由 (1),他向所有女生求过婚。
- 则一定有女生没有被匹配,不妨设为 Amy;
- 由 (2),Amy 从来没有被求过婚;
- 则 Amy 没有被 Zeus 求过婚;
- 由假设和上一条,推出矛盾。
# 正确性证明:稳定性
反证:假设 A-Z 是不稳定对。则分情况讨论:
- 情况 1:Z 没有向 A 求过婚。则 Z 更喜欢当前的对象,与假设矛盾;
- 证明 2:Z 向 A 求过婚,而 A-Z 没有在一起,则 A 更喜欢当前的对象,与假设矛盾;
综上,假设不成立。
# 思考
- 如何用算法实现?时间复杂度?(用数组即可,时间复杂度 )
- 如果有多种稳定匹配,GS 算法得到的是哪一种?
# 多种稳定匹配情况——GS 男生最优,女生最劣
定义:如果存在一组稳定匹配,其中男生 m 为女生 w 配对,则定义他们为彼此的合法伴侣。
结论:GS 算法得到的是男生的最优解,女生的最劣解(男生匹配到的伴侣是最优的合法伴侣,女生匹配到的伴侣是最劣的合法伴侣)。
证明 GS 算法得到的匹配 S* 是男生最优的(男生匹配到的伴侣是最优的合法伴侣):(反证)
- 假设某男在 S* 中匹配到了不是最佳合法伴侣的伴侣。由于男生是以降序求婚,有男生被其最佳合法伴侣拒绝过。设第一个被最佳合法伴侣拒绝的男生为 Y,其最佳合法伴侣为 A。
- 设在另一个稳定匹配 S 中,女生 A 和男生 Y 在一起。
- 在 S* 中,女生 A 拒绝过男生 Y,则女生 A 一定和某男生(设为 Z)在一起了(女生拒绝男生的充要条件是女生和她更喜欢的男生在一起)。则可得女生 A 对男生的好感度中,Z > Y (3)。
- 设在 S 中,男生 Z 和某女生 B 在一起。
- 由于在 S* 中,男生 Y 是第一个被拒绝的,所以此时男生 Z 还没有被拒绝过。此时男生 Z 和女生 A 在一起了,所以男生 Z 还没有向女生 B 求过婚(否则 Z 需要先被 B 拒绝,才能和 A 在一起)。则男生 Z 的好感度中,A > B (4)。
- 在稳定匹配 S 中,A-Y 在一起,B-Z 在一起。而由 (3)(4),A-Z 对彼此的好感度高于他们的当前伴侣 B(Y),因此,推出匹配 S 是不稳定的,矛盾。
问题得证。
有意思的是,男生的最优是以女生的最劣为代价(在 GS 算法中,女生匹配到的伴侣是最劣的合法伴侣),这可以由男生最优这一结论简单的推出:
- 假设在稳定匹配 S* 中,女生 A 和 男生 Z 在一起。而女生 A 的最劣合法伴侣是某男生 Y。则女生 A 对男生的好感度中,Z > Y (5)。
- 设在稳定匹配 S 中,女生 A 和某男生 Y 在一起,男生 Z 和 女生 B 在一起。
- S* 中 A-Z 在一起。由 S* 中男生最优的结论,男生 Z 对女生的好感中,A > B (6)。
- 在稳定匹配 S 中,A-Y 在一起,B-Z 在一起。而由 (5)(6),A-Z 对彼此的好感度高于他们的当前伴侣 B(Y),因此,推出匹配 S 是不稳定的,矛盾。
问题得证。
# 问题拓展:将病人安排在医院
没有做过多研究,仅作摘抄。
Men ≈ hospitals, Women ≈ med school residents
Variant 1. Some participants declare others as unacceptable. (resident A unwilling to work in Cleveland) Variant 2. Unequal number of men and women. Variant 3. Limited polygamy. (hospital X wants to hire 3 residents)
Def. Matching S unstable if there is a hospital h and resident r such that:
- h and r are acceptable to each other; and
- either r is unmatched, or r prefers h to her assigned hospital; and
- either h does not have all its places filled, or h prefers r to at least one of its assigned residents.
# 算法复杂度分析
渐进复杂度分析。
渐近分析(asymptotic analysis、asymptotics),在数学分析中是一种描述函数在极限附近的行为的方法。 有多个科学领域应用此方法。 例子如下: 在计算机科学中,算法分析考虑给定算法在输入非常大的数据集时候的性能。——维基百科
这些都是函数的集合。为什么用 “”而不用 "",只能说是习惯。
主要是想说说另外两个非紧上界、下界。
对于任何正常数 ,存在正数 使得对所有 有:
对于任何正常数 ,存在正数 使得对所有 有:
和上面的区别就是这是对于任何 都满足,因此必须要在数量级上非紧,才能使得对于任何 都满足。
这还很像极限的定义:
但是不完全一样。如果拿极限定义, 就不满足 了。
传递性、对称性、反身性、互对称性、算术运算。
# 贪心算法
实例:线段覆盖。
证明贪心的正确性的几种方法:
- 试图说明在每一步以后,贪心算法至少和别的算法一样好。
- 如果每一个解都有值,找到一个界,并证明贪心能够达到这个界。
- 交换论证。证明每一个解通过一步步的交换,在不变差的前提下,逐渐变为贪心的解。
# 分治算法
分治复杂度计算:
若 ,且 则 。(构造等比数列或列出递归树证明)
还有更通用的(但是好复杂):
若 $T(n) = \begin{cases}1 & \text{n=1} \\kT(\frac{n}{m})+f(n) & \text{n>1} \end{cases}$ 则 $T(n)=n^{log_mk}+\sum_{j=0}^{log_mn-1}k^j f(\frac{n}{m^j})$
不如使用主方法。
注意分治递推表达式里面的常数 推出来和 的次数是有关系的。
# 递归表达式处理
可参考《算法导论》或其他书籍的递归理论。
- Substitution method(代换法,猜结论,然后用第二数学归纳法证明)
- Recursion-tree method(递归树法)
- Master method(主方法
即套公式法)
# 主方法
主方法看起来复杂,其实也不复杂。
对于表达式 , 其中 和 是常数,, 是一个渐进正的函数(渐进函数,并且是增函数),其中 指 或 :
- 若对于某常数 ,有 ,则
- 若 ,则
- 若对于某常数 ,有 ,且对常数 与所有足够大的 ,有 ,则
主方法其实是在说这个事情:
对于 ,其最终算出来的复杂度为某两项之和,并且前一项化出来肯定是 。
主方法做的事情,就是为了在某些条件下,就可以直接判断哪一项的复杂度更高(然后忽略掉另一项)。
而第一、三条的奇奇怪怪的形式是为了表示一句话:“如果后一项的复杂度低于/高于 ”。
在渐进复杂度中没有“复杂度低于”的这种表示法,只能引入 来表示复杂度的高于、低于。于是看起来才这么复杂,为了严谨性不得不牺牲可读性。
剩下具体的内容就不再展开了,因为涉及到了主方法的证明了。
# 分治实例
用分治加速大数乘法:将大数分为前半段和后半段计算。注意要尽量在代数上减少乘法的次数,不能直接跑。

用分治加速矩阵乘法:对矩阵分块,再经过一波玄学操作,能把 8 次乘法()减少到 7 次,从而把复杂度降到 。

# 动态规划
DP 是为了解决递归算法中的重复计算。
DP 可以写为递归形式,也可以写为自底向上的循环形式。
# 0-1 背包问题
时间复杂度:,
不是对于输入量的多项式复杂度,而是输入数值的多项式复杂度(输入量是输入数值取 )。可称为伪多项式时间复杂度,Pseudo-polynomial)。
是 NP 问题。
0-1 背包有多项式复杂度的近似算法,解的误差在 0.01% 以内。
# 序列比对
把两个长度为 m 和 n 的字符串通过 mismatch 和 gap 使得两个字符串匹配。每个 mismatch 和 gap 的代价已知。求总代价的最小值。

跑一个 的 DP 即可。
这是目前最快的算法,但是对于计算生物学来说,两个 10GB 的字符串会很难受。
# 网络流
见另一篇博客。
# NP 和难以计算的问题
讲 NP 之前,我们得先来聊聊什么是归约。
归约,是把看起来不相关的两个问题的解决方法联系起来。这样,就能用一个已知为(公认为) NP 的问题,证明一堆问题是 NP 的。
# 多项式归约
问题 被多项式归约(polynomial reduces to)问题 ,定义为,对于问题 的任意一种情形,都能通过进行以下操作完成:
- 多项式次标准操作 和,
- 多项式次解决问题 的方法。
记作:。
这么做的目的,是将问题按(在多项式时间内解决的)难度分类。以下是分类的技巧:
- 如果 ,而 能在多项式时间内解决,则 也能在多项式时间内解决。
- (1 的逆否命题)如果 ,而 不能在多项式时间内解决,则 也不能在多项式时间内解决。
- $(X \leq _p Y) \wedge (Y \leq _p X) \Leftrightarrow X \equiv _p Y $。
# 归约的技巧
- Reduction by simple equivalence.(简单恒等)
- Reduction from special case to general case.(从特殊到一般)
- Reduction by encoding with gadgets.(利用一些小技巧进行归约)
# 简单恒等:独立集 与 顶点覆盖
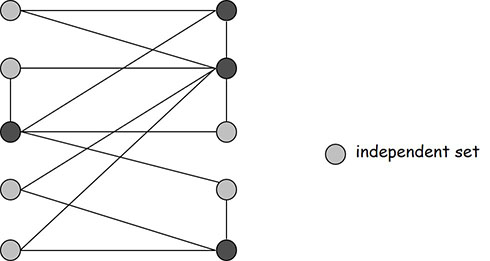
独立集:给定一个图,在图中找到一个点的集合,使得集合中任意两点之间都没有线段。 下图的最大独立集大小为 6。
点覆盖:给定一个图,在图中找到一个点的集合,使得图中的所有边的两个顶点至少有一个在集合里。
下图的最小点覆盖是 4。
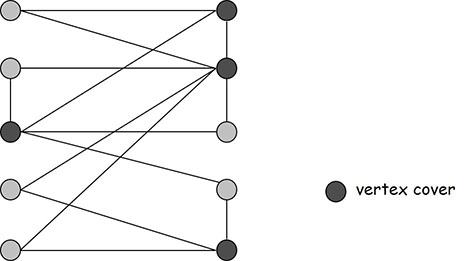
看两个描述就觉得有互补的关系,而看这两张图,就更明显了。最大独立集问题和最小点覆盖问题是否是互补的呢?
是的!最大独立集问题 最小点覆盖问题。
证明:
只需要证明 是独立集的充要条件是 是点覆盖。
必要:设 为独立集。
, or
or
是点覆盖; 充分:设 为点覆盖。对于 中的任意两点 ,二点之间必没有边,否则至少有一点必须被加入点覆盖 。所以 是独立集。
# 从一般到特殊:集合覆盖 与 顶点覆盖
集合覆盖:给定全集 、它的一些子集 和一个整数 ,问能否从所有子集 中选取不多于 个,使得它们的并集为 。
可以证明,顶点覆盖问题 集合覆盖问题。证明思路是,顶点覆盖问题和一类特殊的集合覆盖问题是可以互相等价的。
- 让顶点覆盖中的点是集合覆盖中的集合。
- 让顶点覆盖中的线段是集合覆盖中的元素。
- 让上述线段的两端的顶点是包含了对应元素所存在的集合。(特殊就出现在了这里,要求集合覆盖中的每个元素最多只能出现在两个集合 中)
这样,我们构造出的特殊的最小集合覆盖即等价于最小顶点覆盖。如下图:
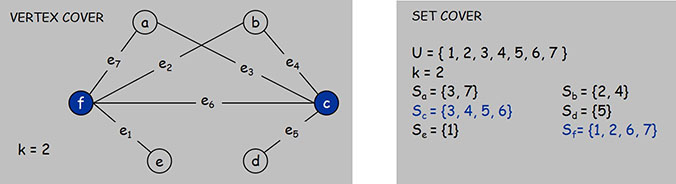
因此,顶点覆盖 集合覆盖。
# 构造的小技巧:3-SAT 与 独立集
先介绍一下析取范式。
简单合取式(Clause):;
析取范式(CNF):。
SAT 问题(Satisfiability)是给定一个析取范式(CNF),判定是否存在一种赋值,使得该范式值为真。
3-SAT 即是,每个 Clause 的变量数不超过 3(不是整个 CNF 涉及到的变量数不超过 3)。如上述的 CNF。
我们可以归约:3-SAT 独立集
构造:(假设问题的 CNF 有 个 Clause)
- 对于每个 Clause 的三个变量,构造三个点,并连接起来构成 个三角形;
- 将所有变量和它的所有否定形式一一连接。
此时,3-SAT 有解,当且仅当该图的最大独立集大小为 。
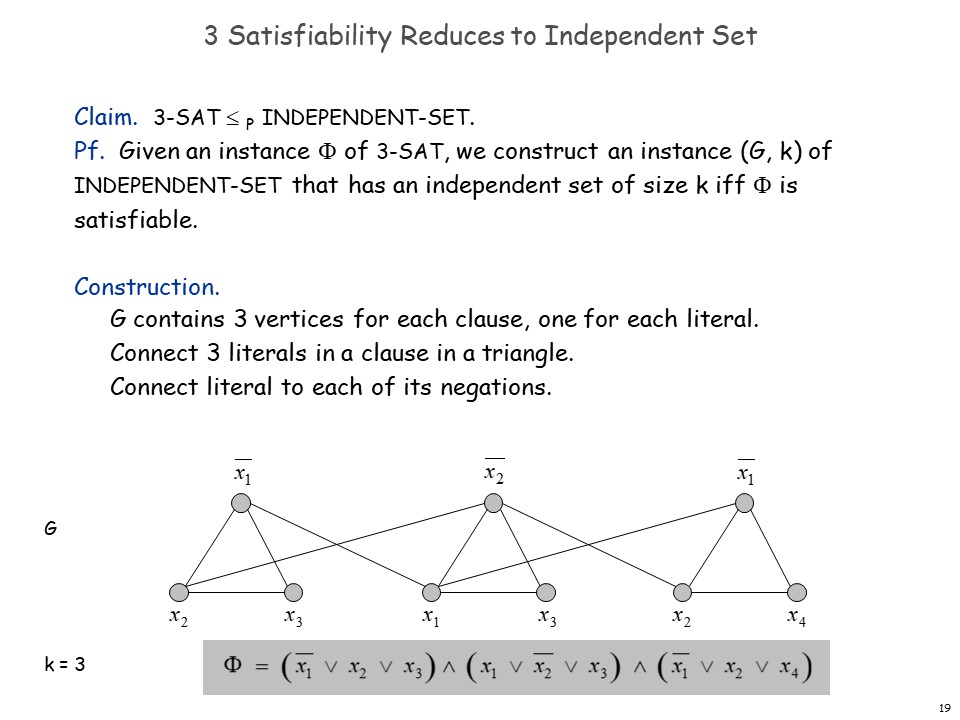
证明:显然 是图的独立集大小的上界。若该图的最大独立集大小为 ,则每个三角形必有一个顶点在该独立集中,且这些点不会同时出现 和 的情况(否则这两点会被相连,与独立集定义矛盾),则可使取的点( 或 )的值为真,没有被赋值的变量任取真或假,即是 3-SAT 的解。
若 3-SAT 有解,则独立集可取解中所有值为真的点,以及值为假的点的取反(即若 为假,取所有 ),对于同一三角形中的点,可在取到的集合去掉任一,即可得到一个大小为 k 的独立集。
# 总结
我们已经证明了:
3-SAT 独立集 顶点覆盖 集合覆盖
# 自身归约
每个问题两个研究方向:决定问题(Decision Problem)和优化问题(Search Problem)。
举个栗子,对于顶点覆盖问题:
决定问题是,是否存在一个小于等于 的顶点覆盖。
优化问题是,找到最小的点覆盖的集合的大小。
显然,对于所有问题,决定问题能被归约到优化问题。
有趣的地方就在于,貌似优化问题也可以归约(指多项式归约)到决定问题,这样,决定问题和归约问题就互相归约了。这种归约叫做自身归约。
如果对于一个问题,如果它能自身归约,于是对于这种问题,我们要想证明 NP,只需要证明决定问题是 NP 的,这样就简化了问题。
而对于目前的所有问题,都可以证明有自身归约的性质(但不代表所有问题一定都有自身归约的性质)。
# 例子:最小点覆盖
下面证明最小点覆盖的优化问题可以归约到决定问题。
- 二分搜索找到最小点覆盖的大小,并设为 k;
- 在图中找到一个点 v 使得删掉 v (及其邻边)的图的有大小为 k-1 的点覆盖;
- 在图中删去点 v,并返回 2 继续执行。
不同的问题证明自身归约有不同的方法,但其实也是有套路可循的。
# P 与 NP
# 决定性问题
决定性问题的严格定义:
是一个字符串(当然也可以是数字)的集合, 是一个字符串,决定问题是需要判断 是否在 中。
多项式时间复杂度:
指对于每个字符串 ,判断 是否在 中的算法所需时间是 长度 的多项式次数。
如判断数字 t 是不是质数的朴素算法,就不是多项式时间复杂度的(是 的)。在 2002 年出现了多项式复杂度的 AKS 算法,。
它的 集合是 。
# 验证(Certification & Certifier)算法
验证算法同样是要判断 是否在 内。不同的是,它可以用到更多的信息 ,以加速判断。
如,判断合数的验证算法需要的 是它的一个因数,这样就能很快判断了。
验证算法的严格定义:对于算法 ,如果对于 中的任意一个解 ,都存在一个 ,使得 ,则称 算法是问题 的一个验证算法。
# NP 的严格定义
先声明一下,NP 不是 P 的反义词!!!!这是新人(包括我)在第一次接触 P 和 NP 时,容易产生的一个很大的误区。
扯完验证算法,就可以说 NP 了,因为 NP 的严格定义是和验证算法有关的。
NP:存在多项式时间的验证算法的决定问题(即能在多项式时间内验证的问题)。
听完这个,可能你会有一万个黑人问号,NP 不就是不能在多项式解决的问题吗????
其实不是,说不定一万年以后就有人证出了某个 NP 问题是多项式可解的呢?
所以呢,NP 的严格定义是存在多项式时间的验证算法,它并没有提及问题本身能否在多项式内是可解的。
不过呢,在平时,一般很多人说的 NP 指的就是目前多项式不可解的问题。这种说法是错误的。
那 NP 为什么叫 NP 啊?它定义里面就没有一个 N 开头的单词啊。
NP 是 nondetermistic (turing machine) polynomial-time,即非确定性图灵机能在多项式时间内解决的问题。啊看不懂看不懂。
好了,那我们如何证明一个问题是 NP 的呢?
。 。。 。。。 。。。。
只需证明能在多项式时间内验证就行了。(不是说要证明他多项式不可解喔别被坑了哈哈哈哈)
验证合数显然是多项式可解的,那验证质数是 NP 呢?只能调用 AKS 跑一遍了,甚至不需要验证算法可以额外提供的 。
# NP-Complete
NP-Complete(NPC、NP完全):所有 NP 问题都能归约到这个问题,并且这个问题也是 NP 的。
顺便说一句,满足第一点的问题也被称为 NP-Hard。这里并不需要证明它不是 NP 的,因为你几乎不能证明一个问题不是 NP 的(毕竟证伪难)。
所以 NP-Hard 包含了 NP-Complete 问题。如上一点的图。
NPC 的意义是,他们是 NP 中最难的问题,因为如果证明其中一个在多项式内有解,则直接证明了 P=NP!
因此,我们不需要花太多精力来找是否存在多项式复杂度的问题。
问题是,第一个 NP-Complete 问题是如何产生的呢?
# P、NP 和 EXP
在讲第一个 NP-Complete 问题之前,这几个概念再理一遍:
P: 使用图灵机能在多项式时间内解决的问题;
NP: 存在多项式时间的验证算法的决定问题;
EXP:使用图灵机能在 的时间内解决的问题( 代表 的多项式)。 NP-Complete:所有 NP 问题都能归约到这个问题,并且这个问题也是 NP 的。 NP-Hard:所有 NP 问题都能归约到这个问题。
有 P NP EXP,NP NP-Hard = NP-Complete。
其中 NP EXP,可由 NP 的定义,解的集合 肯定是有限的,因此能够在指数时间完成枚举即可。
# 第一个 NP-Complete 问题:Circuit Satisfiablity
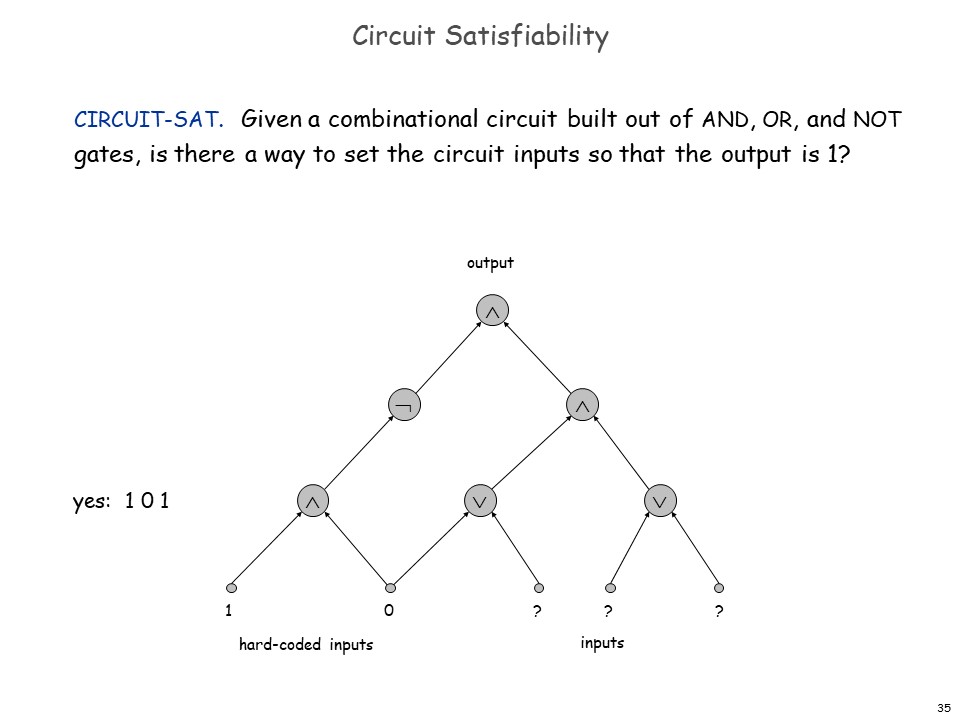

证明的大概思路就是,对于任意 NP 问题,都可以把他的有限的解和验证算法的 t 构成一个逻辑电路,就把所有问题归约为了这个问题。
# 更多的 NP-Complete 问题
我们证明 NP-Complete 的,如果按定义,证明所有 NP 问题都能被归约到这个问题,这也太难了。但是——
有了第一个 NP-Complete 问题,我们就可以通过把已知的 NP-Complete 问题归约到其他问题,(根据归约的传递性)从而证明更多的问题也是 NP-Complete。
以下就是一个 NP-Complete 问题的拓扑图。
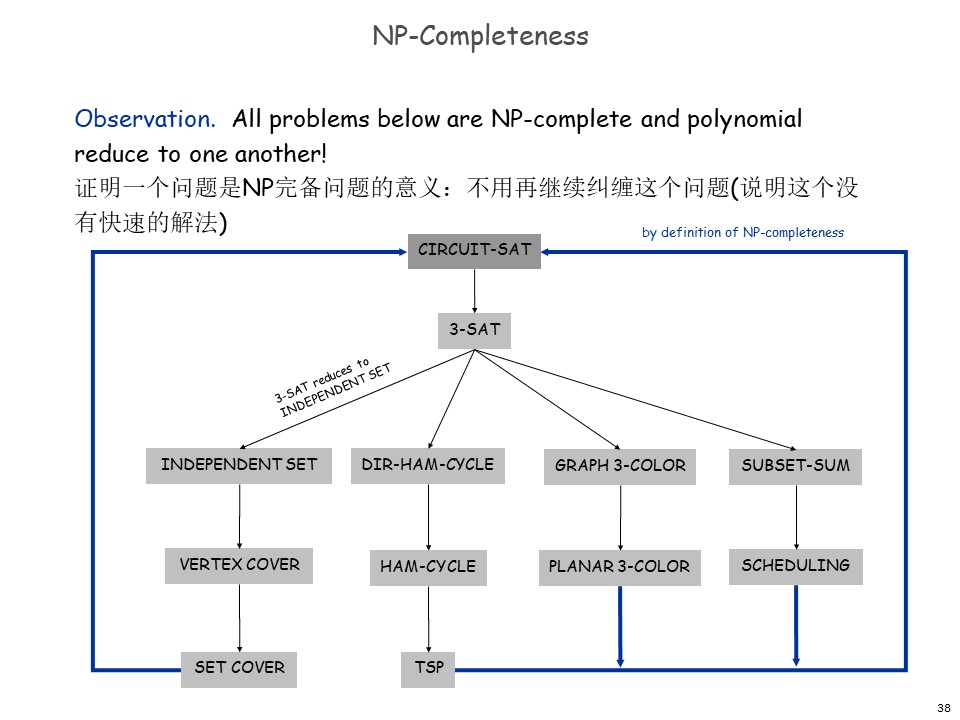
这些问题又分为六个基本大类:
- Packing problems(装箱问题): SET-PACKING, INDEPENDENT SET.
- Covering problems: SET-COVER, VERTEX-COVER.
- Constraint satisfaction problems(约束满足问题): SAT, 3-SAT.
- Sequencing problems: HAMILTONIAN-CYCLE, TSP(旅行商问题).
- Partitioning problems: 3D-MATCHING 3-COLOR.
- Numerical problems: SUBSET-SUM, KNAPSACK.
大多数 NP 问题,要么已知是 P 的,要么已经被证明是 NP-Complete 的了。(也有例外:质因数分解、判断图的同构、纳什均衡等)
看到这里,你大概已经明白了,我们一般说一个问题已被证明多项式不可解,其实不是说的 NP,而是 NP-Complete(准确的说,是 NP-Hard。
虽然 NP-Complete 的定义里面也没有直接提到"多项式不可解",但是,可以注意到的是,NP-Complete 问题多项式可解的充要条件是:P=NP。
接下来,我们要分别阐述六个基本大类里的 NPC 问题。
39-49???????